
Can Claude Code Replace Clay? What's still hard about agentic GTM
50 hours in Claude Code for GTM Engineering - what worked, what broke, and where Clay still lives in my head.

The setup

On April 1st I was asked to give a talk at Deepline’s April Tools Day. I spoke about bespoke sales tooling, the value in building truly custom workflows, and the much greater potential ROI vs commoditized GTM SaaS products.
Feel free to check out the speech here:
Small detail: I had spent less than two hours in Claude Code when I gave that talk.
I’d been on Claude Cowork since February, and I’ve been on Cursor since last spring, so I wasn’t a stranger to AI tooling - but the specific “Claude Code for Clay” thesis I was pre-pitching? I could smell it and certainly see it (as I said in the speech), but I hadn’t been cooking it up myself just yet.
Every part of the talk I gave was real, and the webapps I have built for folks and things I have done are real, but replacing Clay with Claude Code - was still so foreign to me.
After I meme-d my way thru the talk I decided to find out if I could do it. In early April I stopped taking on new clients for two weeks, blocked the calendar, and went deep on figuring out wtf Claude Code was actually capable of for GTM Engineering.
To say I saw the future would be an understatement…

A note on Clay before we go further
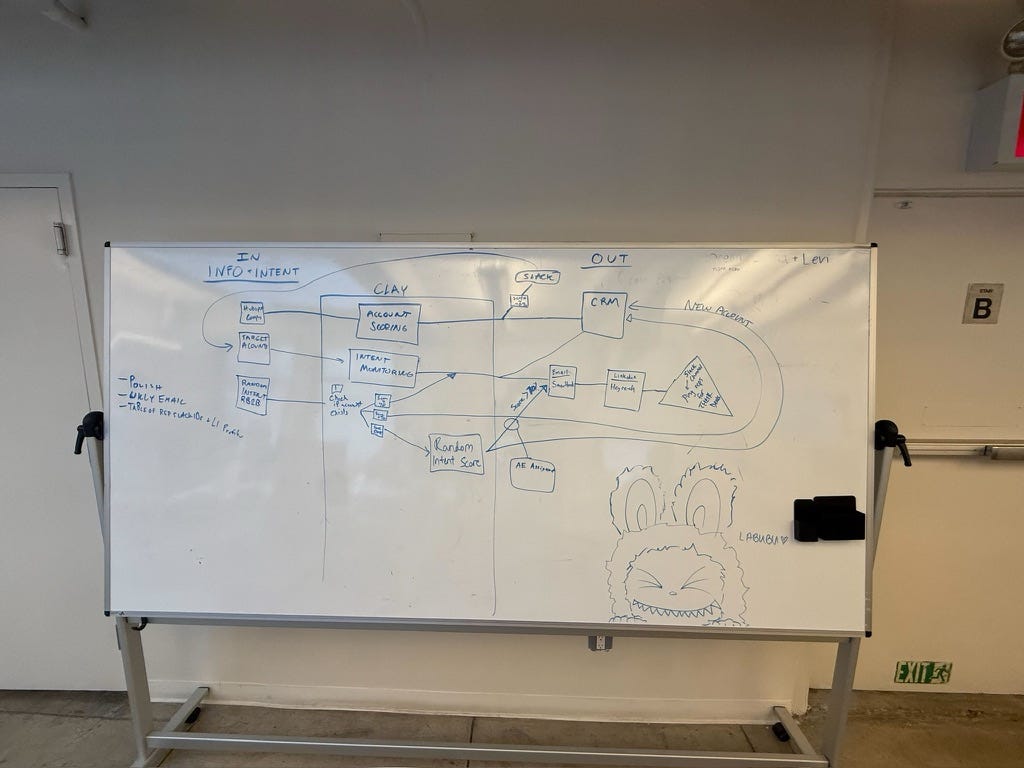
I’m an enormous Clay fan and supporter (FWIW!!!!). Most of my mental model for what a modern GTM workflow even looks like was shaped by Clay. So when I talk about Claude Code below, Clay is the natural reference point - not the antagonist. I think the pricing change just happened to land at a moment where a lot of operators (myself included) were already curious what was possible on the other side, and it created a permission structure to actually find out.
I hate that the pricing change has handicapped folks creativity and made me and others question our entire infra for doing GTME work, but alas here we are.
This isn’t a “replace Clay” piece. It’s a “here’s the unvarnished version of what 50 hours in Claude Code looks like, and where my brain keeps reaching for Clay as comparison” piece.
What was built
I’m gonna use this as a quick note to share what I’ve built and how powerful it is, and you can read into pros and cons below if that’s what you’re here for
Uses Deepline and Apollo / Clay to webhook leads that match title criteria into our database
Cron job runs that filters out bad fit folks, enriches them with LeadMagic, Apify, and a few more providers to pull in all the relevant person level details
Deepline / Claude qualifies and scores folks on a 0-100 scale by persona, and enriches anyone with contact deets if their score hits a threshold
High threshold candidates go to Instantly, top threshold candidates go to Linkedin
Replies are piped into Slack and replied to using a custom AI bot directly from Slack
We run recurring drip campaigns for various events, as well as targeted outbound campaigns for various client searches.
This has been a ton of fun to work on. And big s/o to the Coastal Team (David, Asher, and Kyle) for giving me the reins to build something awesome here, and to be future facing enough to take the risk on building something truly unique
As usual, lots of smoke and mirrors
Claygencies and lead-gen experts posting big diagrams, posting leadmagnets, and claiming they’ve built an outbound engine that has solved world hunger.
The reality is, this tech is still very young (partic for GTME), and few folks are leveraging end to end workflows, let alone being used in production at scale.
Most of the work is being one in one-offs or for test workflows.
Gamechangers in Claude Code

Now lets jump into where I see the differentiators for Claude Code
Speed.

Gone are the days of building 4 Clay tables with 80+ columns, stacking merges, custom-building waterfalls. Tell Claude what you want and watch the workflow get constructed in real time. A scoring pipeline that used to take me a week or two to bullet-proof now takes an hour or two.
Code-first, not AI-first.
A lot of what I’d been spending AI tokens on is deterministic code in disguise: does this title contain “staff”? Does this school contain “Berkeley” or “Cal”? Does this bio contain “beat quota”? These are string matches. In Claude Code they become Python files that run for free forever once written. Across hundreds of thousands of rows, the per-row cost difference is genuinely meaningful - you stop paying tokens for things that aren’t actually language tasks.
A/B testing and rescoring.
Calibrating a scoring model used to mean heuristics, manual tracking, and pushing more volume toward what works week over week. In Claude Code I just ask. “Reweight `senior_eng` to value tenure higher and show me the new top decile.” Done in a sitt. Test, score, push, repeat.
Complex Logic
Clay works up until a limit - cell size limits, complex logic for choosing who to email, when the last time you emailed them was, etc. → this is hard to enable with Clay. Claude Code can use Supabase to index characteristics and run simple DB operations. This is beyond the scope of 95% of Clay’s typical users needs, but is key to scaling your outbound motion.
“Use every part of the animal”
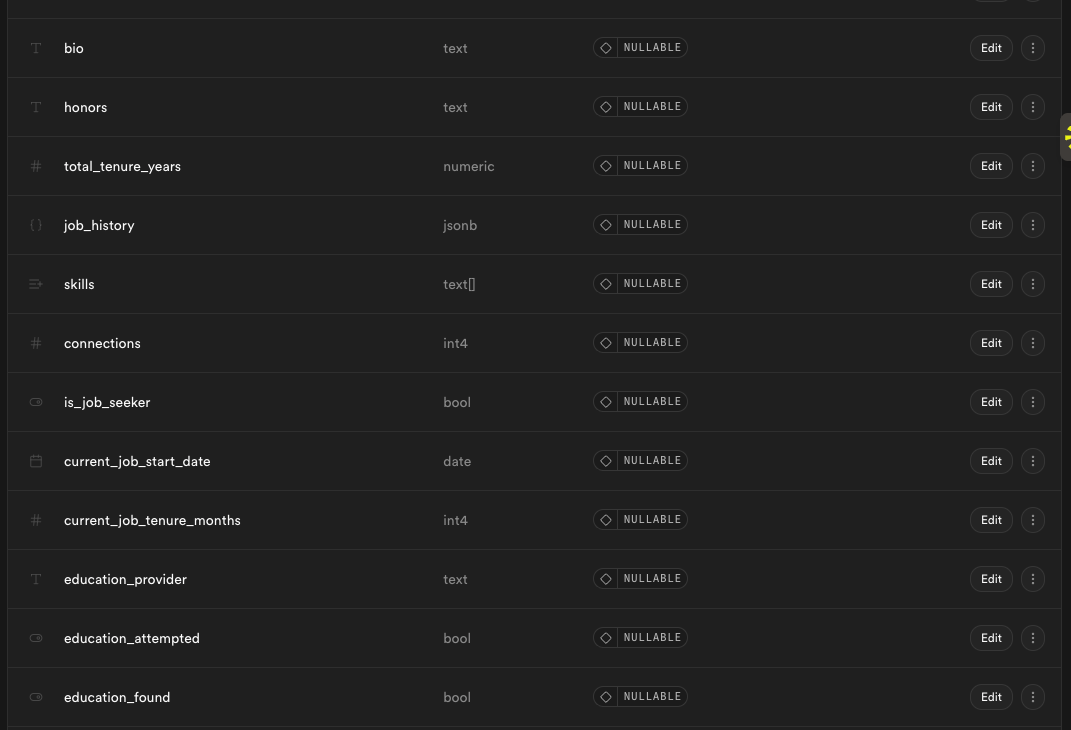
We get so much data from Clay, data vendors, etc. - but you are fundamentally handicapped by the 100 column limits. I end up only using 10-15 datapoints maybe. With Claude code I can use every data point from where someone went to school (all 2+ educations), as well as their follower count, how many promotions they have had, their bio, headline, and so much more! I score most of these which gives me far smoother distributions in ways that aren’t possible with Clay.

How I think about it next to Clay

The way it lives in my head: Clay is reliable and auditable, Claude is a teammate built for speed and fun.
A spreadsheet is auditable by default. Every column is a row of logic you can stare at. Every change is visible. The cost is the ceiling - there’s only so much you can stack into 80 columns before the marginal click stops being worth it.
A teammate is fast and inventive by default. They can build you a whole pipeline in a sitting, including things you didn’t know you needed. The cost is opacity - it lives partly in code and partly in conversation, and you have to actively interrogate it to know what it’s actually doing.
The product that puts a spreadsheet-shaped audit layer on top of an agentic-teammate-shaped tool is going to be a generational GTME platform. Whoever ships that wins.
Where I screwed myself: silent failures

These aren’t really Claude-specific - they’d happen to anyone writing pipelines by hand. But a spreadsheet UI hides them behind a column view and a CLI doesn’t. You feel every single one.
1. Silent failures are the default.
Nothing in our stack threw an error when a parser wrote 91% of senior-engineer work history into the wrong database column. The scorer read the right column, saw nothing, and silently dropped thousands of qualified candidates from outreach. Same energy: forgot to assign senders to your Instantly campaign? It’s not going to send. 200 OK on the push, no email leaves the inbox ;)
2. Vendor docs lag vendor behavior.
A contact-enrichment API returns `200 OK` with an empty payload for private LinkedIn profiles - indistinguishable from a successful pull with nothing to return. We kept re-paying for the same dead URLs until we built our own “empty-but-successful” tag.
3. Schema drift is constant and invisible.
Six different scripts had each forked their own copy of the same NYC/SF location keyword list. One of them slowly drifted to include Bellevue and Seattle, leaking candidates from the wrong cities into a client’s San Francisco-only campaign.
4. Regex-based classification fails quietly with a score of zero.
Our “Staff Engineer” accept list matched the literal string “Staff Engineer” but not the much more common “Staff Software Engineer.” 6,996 staff-level candidates - 80% of the pool - were silently scored zero with no error to surface the mismatch.
5. “Success” at the API layer can hide failure at every downstream layer.
For four straight days every scheduled job on my Mac looked queued and healthy. macOS was silently rejecting all of them because background processes need an explicit permission grant to read iCloud-synced files. Nothing in the logs said so.
6. Pushes succeed at the API and still land nowhere.
A campaign accepted 40 leads and returned `200 OK`, but the campaign had no senders attached. All 40 quietly never sent. We only noticed when a recruiter asked why a prospect had gone cold.
7. Small inefficiencies compound into thousands per quarter.
We were paying a managed proxy 2x the cost of calling the same enrichment API with the key we already owned. Small per-call delta. At hundreds of thousands of calls it added up to a $1,400+ leak before anyone audited the per-row spend.
Where Claude Code itself is still genuinely hard

These aren’t pipeline hygiene problems. These are agentic-execution gaps that no amount of “write more auditors” will fix. These are the open product questions I’m sitting with.
**Rate limits.** Vendors have wildly non-uniform per-second / per-minute / per-day caps. Claude sometimes recognizes a vendor’s documented limit and respects it. Sometimes it doesn’t, and pretends the limit doesn’t exist until a 429 comes back and the run is half-done.
**Repeatability.** I want Apollo people search → LeadMagic → Apify → JS scoring → Instantly to run the same way every time. Sometimes Claude does the whole flow. Sometimes it skips a step. The state of the workflow lives partly in code and partly in conversation context, and only the code part is durable.
**Updates and deprecations.** Apollo recently deprecated a people-search endpoint and I had no idea - found out when something silently 404’d. Endpoints, pricing, rate limits, inputs, outputs all drift. How do I get Claude to surface and migrate to new endpoints on its own as the world moves? Open question.
**Waterfall design.** Deepline abstracts away the multi-API-key problem, which is great. But knowing which vendors exist, which to try in which order, and which to fall back to - is that part of the GTME alpha? Or is the alpha purely ideation + execution, with the vendor stack as a commodity underneath? I genuinely don’t know yet.
**Cursors + pagination.** Some vendors burned hundreds of dollars in credits because we couldn’t reliably paginate or resume a cursor mid-run. Agentic tooling that doesn’t handle pagination state cleanly is a money leak waiting to happen.
Whoever wins will build the auditability layer

Every single silent failure on that list was discovered by writing an explicit auditor *after* the fact. The hard part of building data pipelines - agentic or otherwise - is that the system can’t tell you what it doesn’t know to look for. You have to interrogate it.
The talk I gave on April 1st was right about the destination and wrong about how close we are. The tooling that wins won’t be the one that does more - it’ll be the one that lets a second operator pick up where I left off without re-discovering every silent failure I already wrote an auditor for.
If you’re a GTME and you’ve been curious: pick one workflow you already know cold - a TAM build, a persona scoring pass, an anniversary trigger - and try porting it into Claude Code over a weekend. Don’t try to rebuild your stack. Just one workflow. The point isn’t to migrate. The point is to feel the shape of the tool against something you already understand.
Let me know what you think and what you’re building! And check out OneGTM for my help if you need it!
Your stance in this pic has me listening to this like a JV kid who dressed out on Friday night and is witnessing the GTM head coach pregame speech
The replace-Clay framing skips the brittleness layer. Clay’s value isn’t the prompt, it’s the auth, the rate limits, the integrations holding the workflow together. Claude Code wins inside the IDE. The agentic GTM stack still dies at the seams, not at the model.